目录
一、前言
- 最近,项目有几个表要从 MySQL 实时同步到 另一个 MySQL,也有同步到 ElasticSearch 的。
- 目前,公司生产环境同步,用的是 阿里云的 DTS,每个同步任务每月 500多元,有点小贵。
- 其他环境:MySQL同步到ES,用的是 CloudCanal,不支持 数据转换,添加同步字段比较麻烦,社区版限制5个任务,不够用;MySQL同步到MySQL,用的是 debezium,不支持写入 ES。
- 恰好3年前用过 SeaTunnel 的 前身 WaterDrop,那就开始吧。本文以 2.3.1 版本,Ubuntu 系统为例
二、开源数据集成平台SeaTunnel
1. 简介
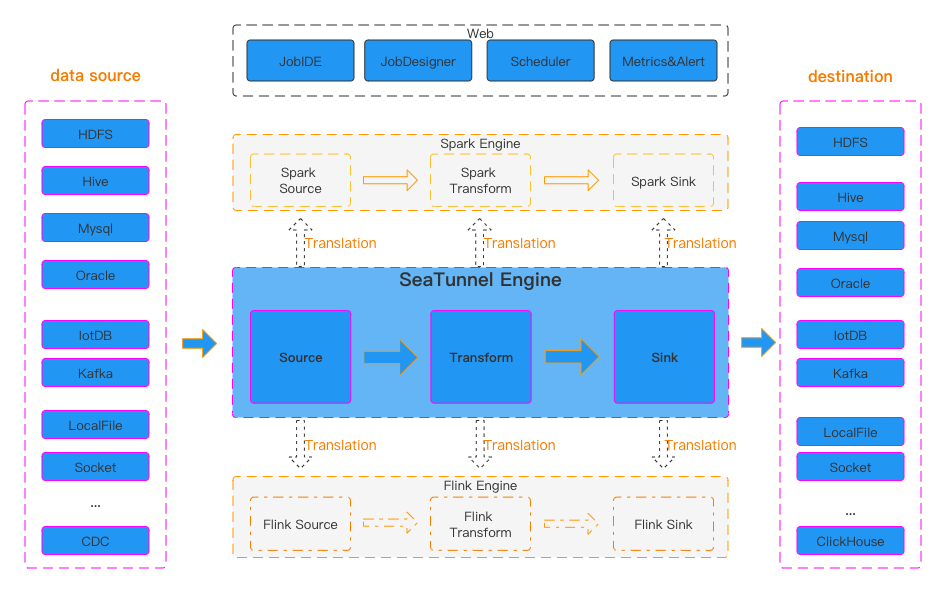
- SeaTunnel 是 Apache 软件基金会下的一个高性能开源大数据集成工具,为数据集成场景提供灵活易用、易扩展并支持千亿级数据集成的解决方案。
- Seaunnel 为实时(CDC)和批量数据提供高性能数据同步能力,支持十种以上数据源,已经在B站、腾讯云、字节等数百家公司使用。
- 可以选择 SeaTunnel Zeta 引擎上运行,也可以在 Apache Flink 或 Spark 引擎上运行。
2. 安装
- 下载,这里选择 2.3.1 版本,执行 tar -xzvf apache-seatunnel-*.tar.gz 解压缩
- 因为 2.3.2 版本,MySQL-CDC 找不到驱动,bug修复详见
| |
3. 安装 connectors 插件
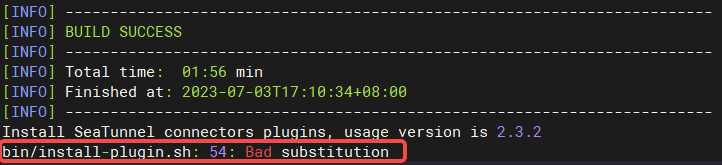
- 执行 bash bin/install-plugin.sh,国内建议先配置
maven镜像,不然容易失败 或者 慢 - 官方文档写着执行 sh bin/install-plugin.sh,我在 Ubuntu 20.04.2 LTS 上执行报错(bin/install-plugin.sh: 54: Bad substitution),我提了PR
4. 编写配置文件
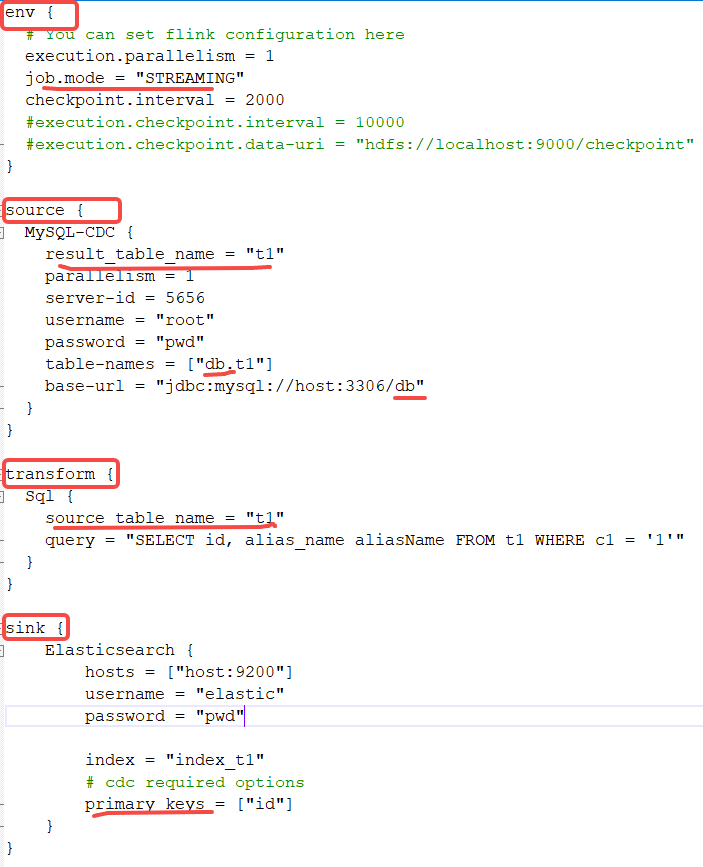
- config 目录下,新建配置文件:如 mysql-es-test.conf
- 添加 env 配置 因为是 实时同步,这里 job.mode = “STREAMING”,execution.parallelism 是 并发数
| |
- MySQL 实时同步,需开启 binlog
- 添加 数据源 配置
result_table_name 取个 临时表名,便于后续使用。table-names 必须是 数据库.表名,base-url 必须指定 数据库。
startup.mode 默认是 INITIAL,先同步历史数据,后增量同步,详情点击
| |
| |
- 添加 输出 配置 CDC 实时同步 es,必须配置 primary_keys
| |
- 最终配置截图
5. 启动任务
这里以 本地模式为例,另有 集群、spark、flink 模式。
| |
三、总结
- 开源数据集成平台SeaTunnel 能够比较方便的进行 MySQL 实时同步到 es 等,免费,还方便添加 同步字段。更多强大功能,请看官方文档。
- 新版本自带 同步引擎,不用依赖 spark、flink 等运行,降低了 小数据量同步场景 部署复杂度
- 新版本开始提供 UI界面,目前强依赖 调度平台 Apache DolphinScheduler
